Od assembly k operačním systémům
Při psaní kódu většinou nepřemýšlíme o tom co se vlastně děje pod kapotou našeho počítače. Znalost toho jak věci skutečně fungují, je při psaní kódu (hlavně low level jazyků), čtení assembly nebo binary analysis neskutečně užitečné. V tomto blog postu se naučíte základu RISC-V assembly, jak se běžné vzory v jazyce C mapují do assembly a něco málo o operačních systémech na kterých váš kód běží.
Jedno z největších prozření které můžete mít jako programátor je že počítače nejsou příliš chytré. Jediné co pořádně dokážou je sekvenčně zpracovávat příkazy jeden po druhém. Těmto příkazům říkáme instrukce a každá instrukce je doopravdy jednoduchá: vynásob tyto dvě hodnoty, přesuň tuhle hodnodu odsuď sem, spusť instrukce co jsou támhle.
V té nejjednoduší podobě počítač vypadá nějak takhle:
Instruction *instructions = ...
CPU cpu = CPU {
.pc = ...
// other cpu properties
};
while (true) {
Instruction ins = instructions[cpu.pc];
switch(ins.opcode) {
// do stuff
};
cpu.pc++
}RISC-V Assembly
Výše zmíněný array instruction je sekvence instrukcí které jsou v nějákém binárním formátu uchovávají informace o tom co má procesor udělat.
V případě RISC-V je každá instrukce 32-bitové číslo.
Například číslo 0x02050593 přičte 32 k registru a0 a výsledek uloží do registru a1.
Tohle vám nemusí moc dávat smysl ale když se na číslo koukneme v binárce můžeme vidět jednotlivé části instrukce které toto určují.
0b000000100000 01010 000 01011 0010011
| | | | |
immedieate rs1 alu rd opcodeopcode 0010011 (nebo operation code) říká procesoru že se jedná o ALU Immediate operaci.
rd je kam má být výsledek uložen.
alu značí jakou operaci má ALU provést, v tomto případě 000 značí operaci sčítání.
rs1 označuje zdroj s kterým CPU pracuje (resource) a immediate je okamžitá hodnota a zároveň druhý zdroj.
Naštěstí v dnešní době nemusíme naštěstí nemusíme psát instrukce takhle.
Namísto toho napíšeme textovou reprezentaci instrukce jako třeba addi a1, a0, 32 a potom jiný program kterému říkáme assembler vytvoří binárku z tohoto textu.
Pokud si chcete přečíst více o tom jak se kódují instrukce můžete zde
Krátká poznámka k jazyku assembly
Každý počítač má svou vlastní instrukční sadu máme instrukční sady jako RISC-V, x86 nebo ARM, a protože assembler mapuje přímo na binární kód, znamená to, že každá architektura má svůj vlastní "jazyk" assembly. Assembly, o kterém budu mluvit v tomto příspěvku, je assembler RISC-V, konkrétně riscv64gc. Výhodou RISC-V assembly je, že je opravdu jednoduchš, takže na něm pochopíte všechny důležité koncepty aniž by se ztratily v moři složitosti (koukám na tebe x86).
Syntaxe
V následujících příkladech potřebujete znát základní syntaxy assembly.
Instrukuce: těch uvidíte zdaleka nejvíce nejčastěji mají následující vzhled:
addi a1, a0, 32,add a1, a2, a3nebocall printfty se poté přemění na binárku.Lables: sestávají z dvou částí, jména a dvojtečky. Používají se, aby instrukce mohly ukazovat jinam do programu.
Directives: directivů je velké množství a ovlivňují jak assembler pracuje. Nejdůležitější pro náš je
.sectionkterý udává jak interpretovat symboly a.globlkterý zveřejňuje symboly.
Registry v RISC-V
Jedna z věcí která dělá RISC-V assembly tak čitelné je pojemnonání registrů.
RISC-V má 32 obecných registrů které jsou pojmenované x0 až x32, ale navíc mají takzvaná "ABI jména".
Užitečnost těchto jmen výjde více na jevo až budu mluvit o calling convention.
Jeden z nejdůležitějších registrů je x0 kterému se říká zero. Čtení z tohoto registru vrátí vždy nulu a zápis bude ignorován.
Tohle chování se hodí, protože pomocí něho lze zapsat spoustu chování na které by jinak byla potřeba speciální instrukce.
Další důležité registry jsou aX registry které se používají pro argumenty funkcím a sX s kterýma se jednoduššeji pracuje (o tom více později).
Zde je tabulka všech registrů k které se můžete kdykoliv později vrátit
| Registr | ABI | Použítí | Zachován při volání |
| x0 | zero | vždy vrací nulu, ignoruje zápis | n/a |
| x1 | ra | retrurn address pro skoky | ne |
| x2 | sp | stack pointer | ano |
| x3 | gp | global pointer | n/a |
| x4 | tp | thread pointer | n/a |
| x5 | t0 | dočasný (temporary) registr 0 | ne |
| x6 | t1 | dočasný registr 1 | ne |
| x7 | t1 | dočasný registr 2 | ne |
| x8 | s0 nebo fp | úložný registr 0 nebo frame pointer | ano |
| x9 | s1 | úložný registr 1 | ano |
| x10 | a0 | vratná hodnota nebo argument 0 | ne |
| x11 | a1 | vratná hodnota nebo argument 1 | ne |
| x12 | a2 | argument 2 | ne |
| x13 | a3 | argument 3 | ne |
| x14 | a4 | argument 4 | ne |
| x15 | a5 | argument 5 | ne |
| x16 | a6 | argument 6 | ne |
| x17 | a7 | argument 7 | ne |
| x18 | s2 | úložný registr 2 | ano |
| x19 | s3 | úložný registr 3 | ano |
| x20 | s4 | úložný registr 4 | ano |
| x21 | s5 | úložný registr 5 | ano |
| x22 | s6 | úložný registr 6 | ano |
| x23 | s7 | úložný registr 7 | ano |
| x24 | s8 | úložný registr 8 | ano |
| x25 | s9 | úložný registr 9 | ano |
| x26 | s10 | úložný registr 10 | ano |
| x27 | s11 | úložný registr 11 | ano |
| x28 | t3 | dočasný registr 3 | ne |
| x29 | t4 | dočasný registr 4 | ne |
| x30 | t5 | dočasný registr 5 | ne |
| x31 | t6 | dočasný registr 6 | ne |
| pc | none | program counter | n/a |
Každý z těchto registrů má 64 bitů. Velikost registru určuje na jak velkých datech instrukce pracují a takzvanou velikost slova.
Základní Instrukce
V téhle sekci vám ukážu jak se časté vzory v jazyce C implementují v assembly.
Každá ukázka je C kód a jeho assembly výstup.
Pokud chcete máte vlastní RISC-V virtuálku nebo RISC-V toolchain můžete výstup získávat pomocí clang main.c -o main.asm -S -Oz.
Alternativu kterou doporučuji skoro více je používat compiler explorer.
Konstatní hodnoty
Nejzákladnější operací v programování je dávání hodnot proměnnýn: int x = 60.
V RISC-V jsou všechny instrukce 32-bitové, ale do registrů potřebujeme dát 64-bitová data.
To znamená, že na načtení jednoho čísla je potřeba více instrukcí.
V případě že píšeme assembly ručně je nám proto poskytnuta li pseudoinstrukce kterou poté assembler nahradí za instrukce nutné na načtení daného čísla.
long ret_big_num() {
return 9999999999999;
}ret_big_num:
li a0, 9999999999999 ; a0 = 9999999999999
ret ; return a0Toto assembler rozloží na následující instrukce.
ret_big_num:
lui a0, 298023
addiw a0, a0, 917
slli a0, a0, 13
addi a0, a0, -1
retAritmetické Instrukce
Aritmetické instrukce patří k těm nejpoužívanějším instrukcím.
Od čeho jiného jsou počítače než aby počítaly.
Syntaxe je obvykle operace output_reg, input_reg, 12bit_imm nebo operace output_reg, input_reg, input_reg.
Tady jsou nějáké běžné aritmentické operace a jejich intrukce
long operations(long x, long y) {
x = x - y;
x = x * y;
x = x << y;
x = x >> y;
x = x + y;
return x;
}operations:
; x is in a0
; y is in a1
sub a0, a0, a1 ; x = x - y
mul a0, a0, a1 ; x = x * y
sll a0, a0, a1 ; x = x << y
sra a0, a0, a1 ; x = x >> y
add a0, a0, a1 ; x = x + y
retSkoky a větvení
Pomocí skoků a větví (jumps and branches), můžeme modifikovat tok programu. Skrze skoky a větve se implementují loops, ify a switche.
while(true) loop se zkompiluje do nepodmíněného skoku.
int main() {
long x = 0;
while (true) {
x = x + 1;
}
return 0;
}main:
; ... omitted for readability
li a0, 0 ; long x = 0
.loop: ; this is label which we can reference as address
addi a0, a0, 1 ; x = x + 1
j .loop ; jump back to .loopIfy jsou zkompilovány do podmíněných skoků. Povšimněte si, že kompilátor změnil pořadí operací aby byl kód kratší. Pro jistotu jsem přidal více komentářů aby byl příklad pochopitelnější.
long ifs(long b) {
long num = 14;
if (b == 55) {
num = 15;
} else if (b == 73) {
num = 36;
}
return num;
}ifs:
; b is in a0
mv a1, a0 ; a1 = b
addi a2, a0, -73 ; a2 = b - 73
li a0, 36 ; a0 = 36 (num = 36)
; now num is equal to 36
; if b is equal to 73 the program jumps to the label .eq_to_73
; and skips the loading of 14 into num
beqz a2, .eq_to_73 ; if a2 == 0 (b == 73) jump to .eq_to_73
li a0, 14 ; a0 = 14 (num = 14)
.eq_to_73:
; at this point num is equal to 36 is b is equal to 73 else it's 14
addi a1, a1, -55 ; a1 = b - 55
; if b is not 55 it just jumps to the .return label
; the correct value is already loaded for cases when b is not 55
bnez a1, .return ; if a1 != 0 (b != 55) jump to .return
; if b is 55 we load 15 to num
li a0, 15 ; a0 = 15 (num = 15)
.return:
ret ; return numSkoky pod mikroskopem
Ve skutečnosti neexistuje instrukce j .label v realitě se jedná o pseudoinstrukci.
Instrukce na kterou tato pseudoinstrukce expanduje je jal zero, .label.
zero je v tomto případě registr, do kterého ukládáme adresu, ze které skáčeme.
Uložení adresy nám umožní vrátit se na místo, ze kterého jsme skočili.
V tomto případě adresu právě zahazujeme tím, že ji "uložíme" do registru zero.
Poslední částí je offset od aktuální instrukce, na kterou se má skočit.
Offset se vypočítá assemblerem.
Existuje také jalr rd, rs1, offset, který přidá offset k rs1 a uloží aktuální adresu do rd.
Toto nám dovoluje mnohem větší skoky.
Podmíněné skoky se nazývají větvení (kód se větví do více možných stavů).
Instrukce větvení bnez a1, .return je také pseudoinstrukce a rozšíří se na bne a1, zero, .return.
a1 a zero jsou operandy na kterých operace pracuje, bne je: "skoč pokud není rovno". .return je label pro výpočet offsetu.
Instrukce pro větvení jsou beq pro rovnost, bneq pro nerovnost, blt a bltu pro porovnání menší než s přirozenými a celými číly respektive a konečně bge a bgeu pro porovnání větší nebo rovno opět pro přirozená a celá čísla.
Další podmíněné větvení se provádí pomocí pseudoinstrukcí.
Ostatní instrukce
Do ostatních instrukcí patří uhhh... skoro všechny ostatní instrukce.
Například instrukce které nám říkají něco o stavu procesoru jako csrrw.
Také je zde například ecall instrukce která poprosí kernel aby pro vás něco udělal
Breakpoint instrukce nebo "fence" instrukce sem také patří.
Pokud se o těchto instrukcích chcete dočíst více můžete zde
Pseudo instrukce
Psedo instrukce jsou instrukce které pro nás compiler přepíše na jiné a poskytují nám tím chování které jinak instrukční sada neposkytuje. Mezi tyto instrukce patří
nop: instrukce co nedělá nicla: tato instrukce vám načte adresu do registruli: tato instrukce načte konstantu do registrucall: zavolá funkci (více o tomto později)ret: vrátí z funkcebeqz,bnez,bgez,bgt,ble... množství branching instrukcí
Přístup do paměti
Dosud jsme mluvili pouze o jednoduchých proměnných jako long int x = 0, ale ještě jsme nemluvily o pointerech nebo polích.
Zápis
Pointer je proměnná, která obsahuje adresu paměti v které jsou data která nás zajímají.
Pro zápis na tuto adresu použijeme instrukci sd.
void deref(long *ptr) {
*ptr = 5;
}deref:
; ptr is in a0
li a1, 5 ; a1 = 5
sd a1, 0(a0) ; *ptr = a1
retPrvním argumentem je registr s daty, která chceme zapsat, v tomto případě je to číslo 5, které jsme nahráli do a1.
Druhým argumentem je registr s adresou, na kterou chceme zapisovat, v tomto případě je to argument a0, který obsahuje ukazatel ptr.
Existuje také třetí argument, který zapisujeme z venku závorek kolem druhého argumentu 0(a1).
Argument označuje konstantní offset od v registru v bytech.
V tomto případě je to nula, protože chceme zapisovat přímo do této adresy bez jakéhokoli offsetu.
Argumenty jsou tedy v tomto pořadí datový registr, offset(adresní registr)
Offset by byl nenulový, kdybychom chtěli zapisovat do pevně daného offsetu od pointeru.
void deref(long *ptr) {
ptr[3] = 5;
}deref:
; ptr is in a0
li a1, 5 ; a1 = 5
sd a1, 24(a0) ; *(ptr+24) = 5
retHodnota 24 pro offset se vypočítá vynásobením velikosti typu v bytech, indexem (sizeof(long) / 8). * 3 offset se pak přičte k základní adrese.
Předchozí ukázka a následující ukázka se zkompiluje do identického assembly:
void deref_add(long *ptr) {
ptr += (sizeof(long) / 8) * 3;
*ptr = 5;
}deref_add:
li a1, 5
sd a1, 24(a0)
retPokud index neznáme předem musíme offset od základní adresy spočítat za běhu.
void mutate(long *ptr, long index) {
ptr[index] = 5;
}mutate:
; buf is in a0
; index is in a1
slli a1, a1, 3 ; index = index << 3 // this is equivalent to index = index * 8
add a0, a0, a1 ; ptr = ptr + index
li a1, 5 ; a1 = 5
sd a1, 0(a0) ; *ptr = 5
retNačítání z paměti
Načítání z paměti má v podstatě stejnou syntaxi a velmi podobné vzorce jako zápis do pamněti
Argumenty jsou v pořadí cílový registr, offset(adresní registr)
První registr je ten, do kterého se budou data z adresy načítat, druhý argument je registr s adresou, ze které se má načítat, a offset je opět offset v bajtech od základní adresy.
long load(long *ptr) {
return *ptr;
}
long load_s_idx(long *ptr) {
return ptr[3];
}
long load_idx(long *ptr, long index) {
return ptr[index];
}load:
; ptr is in a0
ld a0, 0(a0) ; a0 = *ptr
ret ; return a0
load_s_idx:
; ptr is in a0
ld a0, 24(a0) ; a0 = *(ptr+24)
ret ; return a0
load_idx:
; ptr is in a0
; index is in a1
slli a1, a1, 3 ; index = index * 8
add a0, a0, a1 ; ptr = ptr + index
ld a0, 0(a0) ; a0 = *ptr
ret ; return a0Volání funkcí
Jedna z nejužitečnějších abstrakcí v programování jsou funkce.
Bez funkcí by v našem programu byl velmi rychle extrémní nepořádek.
Naštěstí pro nás funkce existují i v assmebly díky instrukcím call a ret.
Funkce se v jakémkoliv jiném jazyce skládají z několika částí
// list of arguments
int add_one(int x) {
// body of the function
x = x + 1;
// optionally return a value
return x;
}
/*
* ...
*/
// calling the function and passing arguments
add_one(3) // -> 4Bohužel v assembly nemáme to privilegium napsat add_one(3) a očekávat že se všechno dá tam kam má.
Musíme vše udělat instrukci po instrukci.
To nejlepší, co nám RISC-V nabízí je call instrukce která nám uloží návratovou adresu a ret která skočí zpět na návratovou adresu.
Zbytek jako umístění argumentů a návratovou hodnotu si musíme řešit sami.
Vzhledem k tomu že toto všechno musíme řešit samy by se hodil návod který můžu vždy sledovat a bezpečně zavolat funkci.
Ideálně by se hodilo kdyby tento návod byl univerzální abych pomocí něj mohl zavolat funkci z jakékoliv knihovny a ono by to fungovalo.
Potřebujeme tedy nějáký kontrakt který bude dodržovat jak ten kdo funkci volá tak volaná funkce který nám říká kam dát argumenty a návratovou hodnotu a jak se chovat k registrům.
Naštěstí chytří lidi před náma již tento kontrakt vymysleli. Říká se mu calling convention nebo někdy zkáceně callconv. Některé jazyky mají svoji vlastní calling convention která málokdy bývá zdokumentovaná. Aby to bylo horší se callconv může lišit podle operačního systému. Calling convention o které budu mluvit já je Linuxová callconv.
Pitva volání funkce
Kroky volání funkce vypadají takto
Příprava před voláním: Volající vloží argumenty na určená místa. To obvykle znamená jejich umístění do registrů nebo na stack. Volající rovněž uloží registry které nejsou zachovány funkcí (caller saved registers).
Skok do funkce: Volající spustí instrukci
callnebo její ekvivalent v dané architektuře. Tím se obvykle uloží aktuální pozice hodnota program counter a program counter se nastaví na adresu funkceProlog funkce: volaná funkce volitelně provede nějaké nastavení: Nejprve rezervuje místo na stacku a pak uloží všechny registry, které chce použít a má povinost uložit (callee saved registers).
Tělo funkce: Nyní se spustí kód funkce. Odpovědností této části funkce je umístit návratovou adresu na správné místo.
Epilog funkce: volaná funkce ruší to co provedla během prologu. Jedná se například o obnovení stavu registrů a stacku. Na konci této fáze se provede instrukce
ret, která skočí zpět na návratovou adresuObnova po volání: Volající pokračuje ve spouštění. Obnoví stav všech registrů které si před tím volající uložil.
Malé funkce, které používají malé množství registrů, se mohou vyhnout velké části těchto kroků a funkce, které nevolají žádnou jinou funkci (někdy se nazývají listové funkce), se mohou obvykle vyhnout všem témto krokům.
Pojďme se nyní podívat na jednu funkci zblízka jak vše probíhá krok po kroku:
long sum_and_print(long x, long y) {
long sum = x + y;
printf("%li\n", sum);
return sum;
}Zde je výsledné assembly z dovysvětlujícími komnetáři:
sum_and_print:
; This is called function prologue
; It saves return address if needed,
; saves callee saved registers it wants to use.
; The process of putting registers on stack is called spilling
addi sp, sp, -16 ; makes place on stack
sd ra, 8(sp) ; spills return address to stack
; s0 is callee saved register which the function wants to use so it has to be spilled so it's state can be restored.
sd s0, 0(sp) ; spills s0 to stack.
; this is the actual body of the function
add s0, a1, a0 ; sum = x + y
; this label and next to instruction is RISC-V pattern to load address of other label into register
; This pattern is used when dealing with position independent code
; This loads the address of the string "%li" to the a0 argument register where the function printf expects the first argument
.Lpcrel_hi0:
auipc a0, %pcrel_hi(.L.str)
addi a0, a0, %pcrel_lo(.Lpcrel_hi0)
; this moves the sum variable to a1 where printf expects the second argument
mv a1, s0
; call is pseudo instruction
; the call instruction saves the current value of pc register to ra register
; and jumps to the address of the function
call printf
; the function resumes execution after printf
; put the content of s0 register to the a0 register
; we can expect the s0 register to have the same value as before the call to printf
mv a0, s0
; This is function epilogue it undoes the steps the prologue did.
; Resotore the original state of the registers
ld ra, 8(sp)
ld s0, 0(sp)
; restores the state of the stack
addi sp, sp, 16
; ret is pseudo instruction
; it jumps to the address in ra register
ret
.L.str:
.asciz "%li\n"Volající
Přípravu před voláním můžeme vidět těsně před zavoláním printf()
auipc a0, %pcrel_hi(.L.str)
addi a0, a0, %pcrel_lo(.Lpcrel_hi0)
mv a1, s0
call printfBěhem přípravy jsou argumenty dány na určené místo. Argumenty velikosti slova jsou předávány v registrech a0 až a7. Argumenty velké dvě slova se vkládají do dvou registrů. Větší argumenty jsou dány na stack a předány referencí. Zbytek argumentů se dá na stack.
První argument (string "%li\n") je předán odkazem (první argument printf je char *x, takže očekává pointer na hodnotu).
Instrukce auipc a addi spolu s direktivami %pcrel_hi a %pcrel_lo se používají k načítání adres pozičně nezávislým způsobem (kdybychom assembly psali ručně použily bychom la pseudo isntrukci).
Druhý argument se zkopíruje do registru a1, z registru s0, kde je uložen výsledek sčítání.
Komplexnější type signature funkce vyžaduje mnohem více práce s přípravou před voláním.
Po opětovném spuštění funkce se obnoví registr hodnota ra, kde se očekává návratová adresa.
Adresa musela být uložena, protože volání printf() registr přepíše.
Volaná funkce
Prolog a epilog funkce lze vidět přímo v samotné funkci sum_and_print.
sum_and_print:
addi sp, sp, -16
sd ra, 8(sp)
sd s0, 0(sp)
; ...
ld ra, 8(sp)
ld s0, 0(sp)
addi sp, sp, 16
retIntrukce addi sp, sp, -16 zaregistruje 16 bytů na stacku. sp (stack pointer) ukazuje na vrchol zásobníku.
Stack roste směrem dolů (alespoň na většině architekturách) a musí vždy být zarovnán na 16 bajtů to znamená, že musíme vždy odečíst násobek 16ti.
Pak uložíme registry které máme povinnost uchovat (callee saved registers, v tabulce výše jsou označené jako zachované) a budeme je používat.
Tento proces se nazývá spilling.
Díky tomu je použití uložených registrů velmi pohodlné, protože je stačí uložit během prologu, obnovit během epilogu a očekávat, že budou mít stejnou hodnotu i po volání funkce, protože volaná funkce je sama uloží a obnoví.
Pokud by funkce potřebovala nějaké místo pro své proměnné na stacku, rezervovala by si to místo během tohoto kroku.
Pak začne tělo funkce, v chvíli kdy tělo končí by měla být návratová hodnota v označeném místě.
Pro tuto funkci je určené místo v registru a0.
Pokud je návratová hodnota dlouhá dvě slova, umístí se do registrů a0 a a1.
Pokud je návratová hodnota delší, funkce očekává, že volající alokuje potřebné místo předem a předá adresu tohoto místa jako argument do a0, čímž dojde k posunu všech ostatních argumentů.
Epilog pak zruší všechny operace prologu, včetně zmenšení stacku a obnovení spilled registrů.
Poté ret skočí zpět na adresu uloženou v registru ra.
Ve funkcích v příkladech výše nebyly tyto kroky potřeba, protože se jedná o tzv. listové funkce které nevolají žádné jiné funkce.
Protože nevolají žádné jiné funkce, není třeba ukládáat žádné registry a funkce může pro uložení všech výpočtů použít pouze dočasné registry tx a argument registry ax.
Stack
Zásobník je jedním z nejdůležitějších konceptů, který je třeba při práci s assembly pochopit a mít pro něj intuici. Ať už se jedná o debugování nebo binární exploitaci, intuice pro stack může tyto úkoly značně usnadnit.
Podívejme se nyní na několik příkladů, jak se zásobník chová v určitých situacích.
long sum_and_print(long x, long y) {
long prod = x + y;
printf("%li\n", prod);
return prod;
}
int main() {
long x = sum_and_print(25, 17);
return x;
}sum_and_print:
addi sp, sp, -16
sd ra, 8(sp)
sd s0, 0(sp)
add s0, a1, a0
.Lpcrel_hi0:
auipc a0, %pcrel_hi(.L.str)
addi a0, a0, %pcrel_lo(.Lpcrel_hi0)
mv a1, s0
call printf
mv a0, s0
ld ra, 8(sp)
ld s0, 0(sp)
addi sp, sp, 16
ret
; the execution starts just before the main function is called.
main:
addi sp, sp, -16
sd ra, 8(sp)
li a0, 25
li a1, 17
call sum_and_print
sext.w a0, a0
ld ra, 8(sp)
addi sp, sp, 16
ret
.L.str:
.asciz "%li\n"Nyní si projděme instrukci po instrukci, co se děje. (Některé části těla funkce, které nemají vliv na zásobník, vynechám.)
Než se zavolá hlavní funkce a začne se vykonávat napsaný kód, provede se nějáká připrava.
Takto vypadá zásobník, těsně před zavoláním main() funkce.
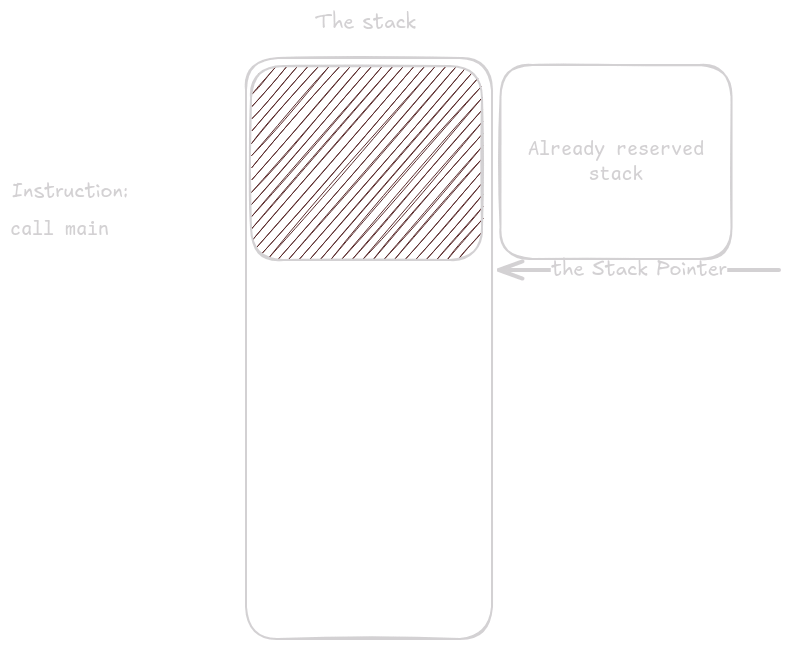
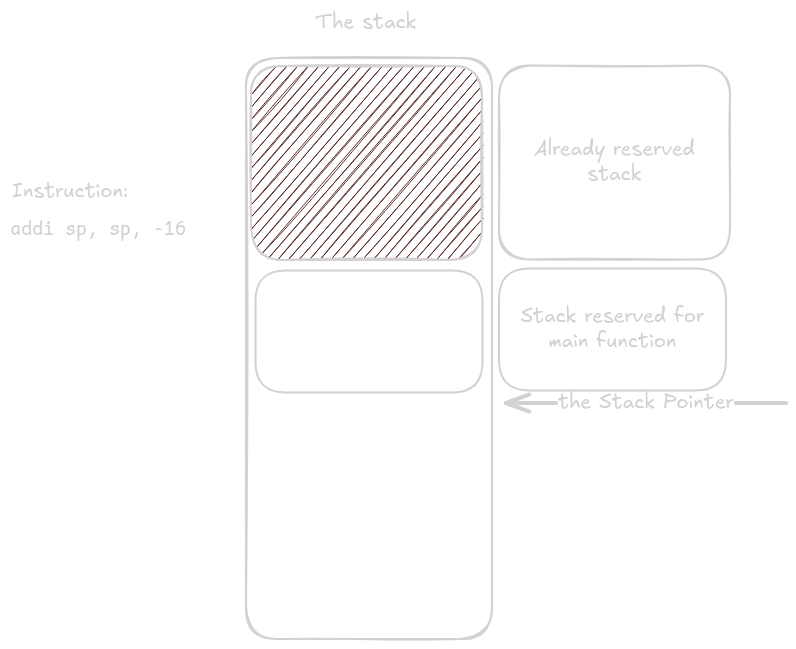
První instrukce main funkce rezervuje místo pro registry, které je třeba uložit.
V tomto případě je třeba uložit pouze registr ra.
Přesto musíme rezerovat 16 bytů místa, aby byl zásobník zarovnaný.
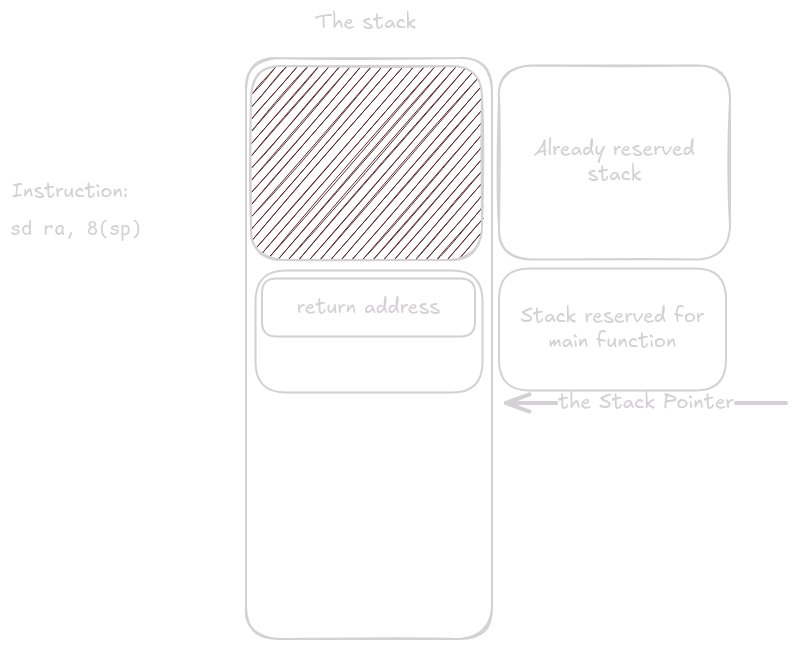
Registr ra se uloží na kladní offset 8 od sp.
Tím zůstane na vrcholu stacku 8 bytů které budou prázdné (zásobník roste směrem dolů, takže vrchol zásobníku je dole).
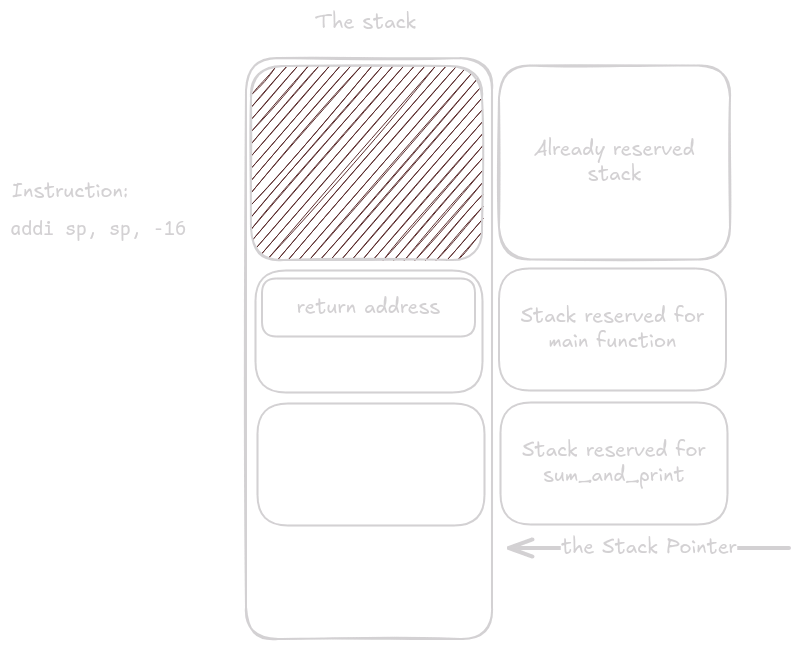
Poté se začne main() funkce spouštět.
V jednu chvíle se během spouštění provede instrukce call sum_and_print.
Funkce sum_and_print() nyní převezme kontrolu nad spouštěním a začne její prolog.
Jako první si funkce sum_and_print alokuje místo na stacku.
Pak se uloží registry. Nejdříve return address a poté registry které má funkce povinnost uložit.
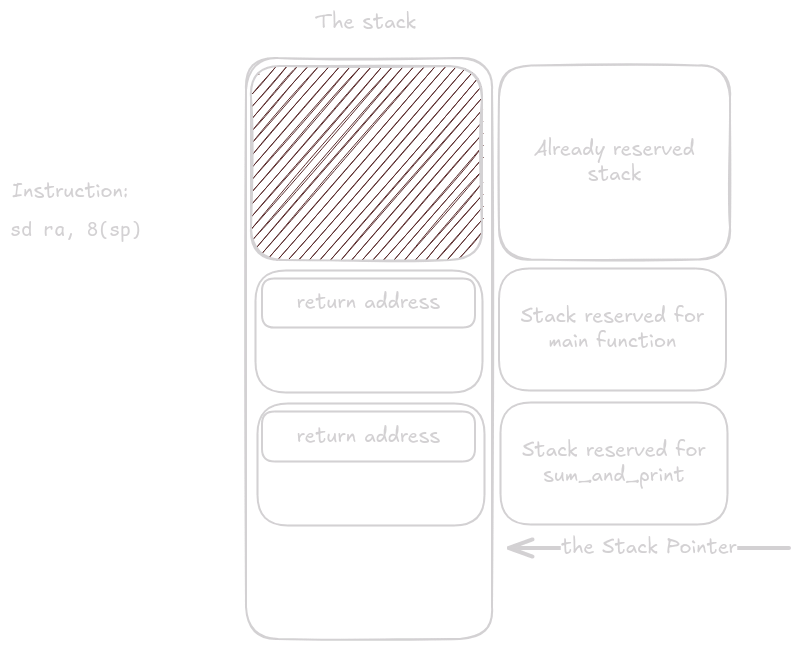
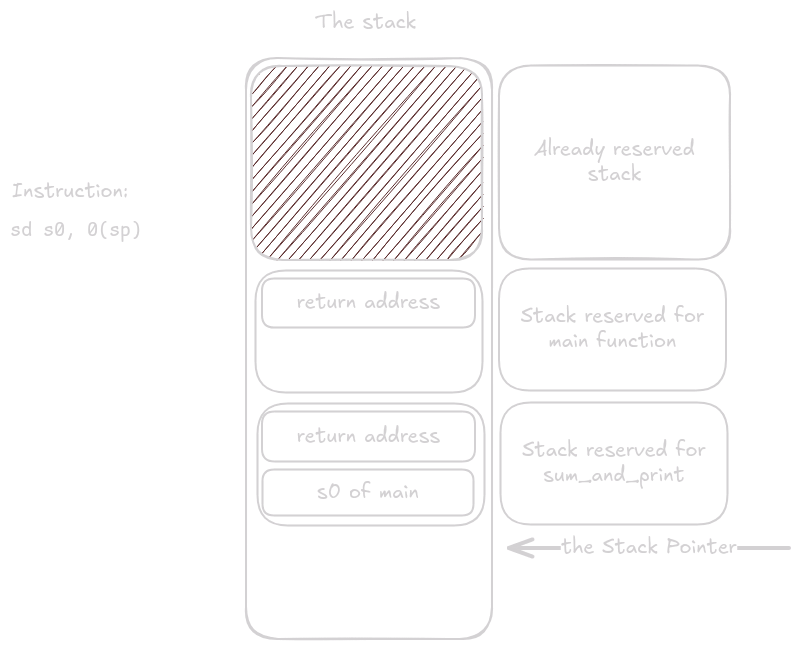
V tuto chvíli začne tělo sum_and_print, provede se volání printf, printf se zarezervuje a uvolní místo na stacku jako každá jiná funkce.
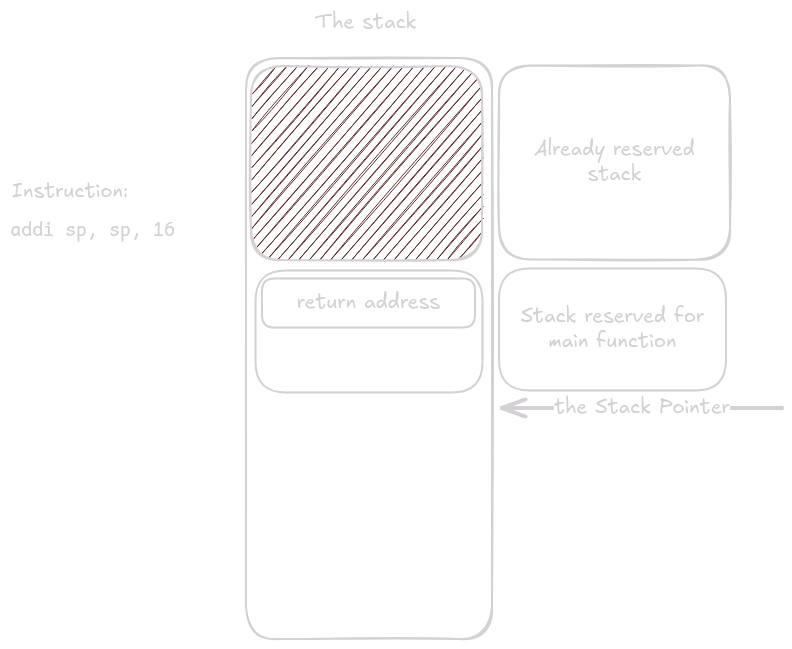
Na konci funkce, když byly obnoveny registry, se místo na zásobníku uvolní pouhým přičtením k stack pointeru.
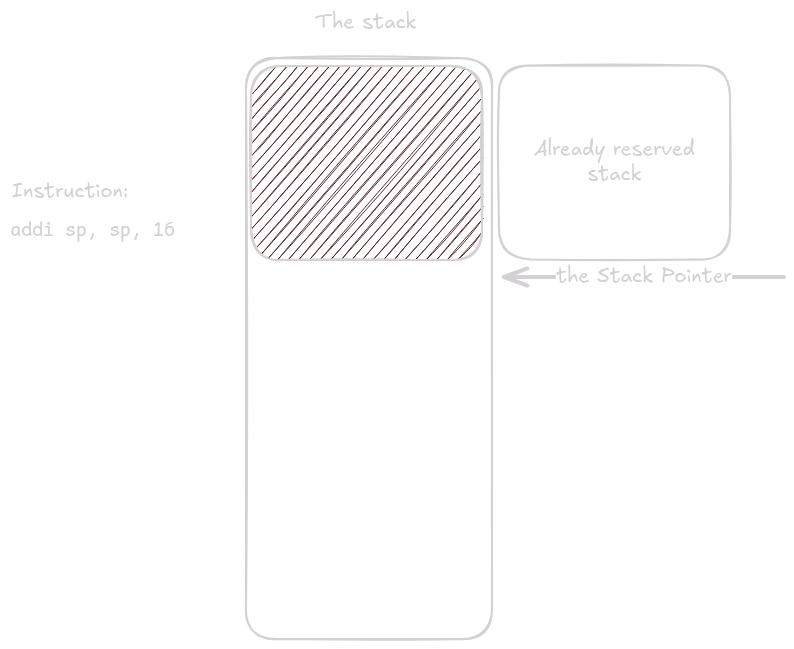
To samé se stane na konci main() funkce
Well to bylo docela jednoduché, pojďme se podívat na něco zajímavějšího.
Tato funkce načte 60 bytů ze standardního vstupu do bufferu buf
void fill() {
char buf[60];
fgets(buf, 60, STDIN_FILENO);
}fill:
addi sp, sp, -80
sd ra, 72(sp)
addi a0, sp, 12
li a1, 60
li a2, 0
call fgets
ld ra, 72(sp)
addi sp, sp, 80
retStejně jako dříve je již nějáké místo na stacku zarezervováno než naše funkce převezme kontrolu.
Jakmile finkce kontrolu převezme zarezervuje si místo pro všechny proměnné a registry co potřebuje uložit.
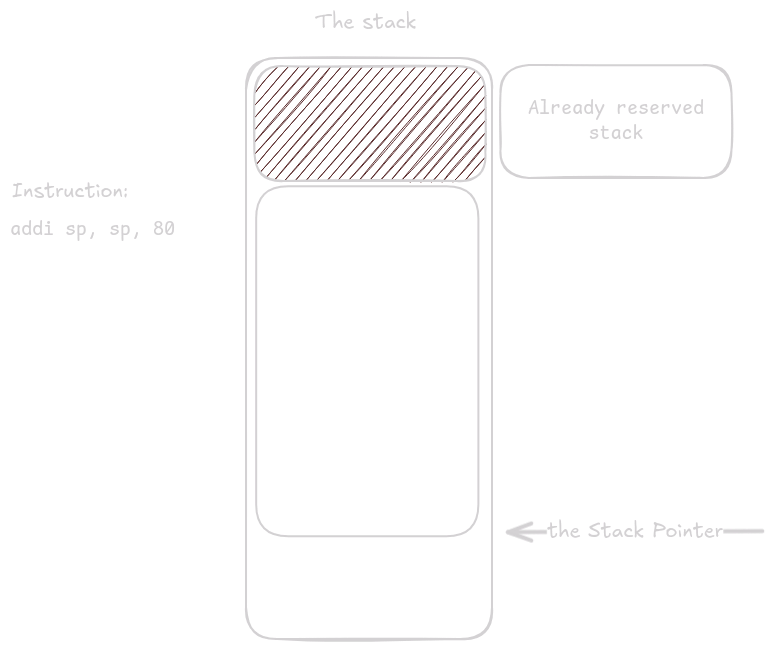
V tomto případě funkce potřebuje 68 bytů, ale protože stack musí být zarovnán na 16 bytů je zarezervováno 80 bytů.
První co se během prologu stane je že ra je uloženo.
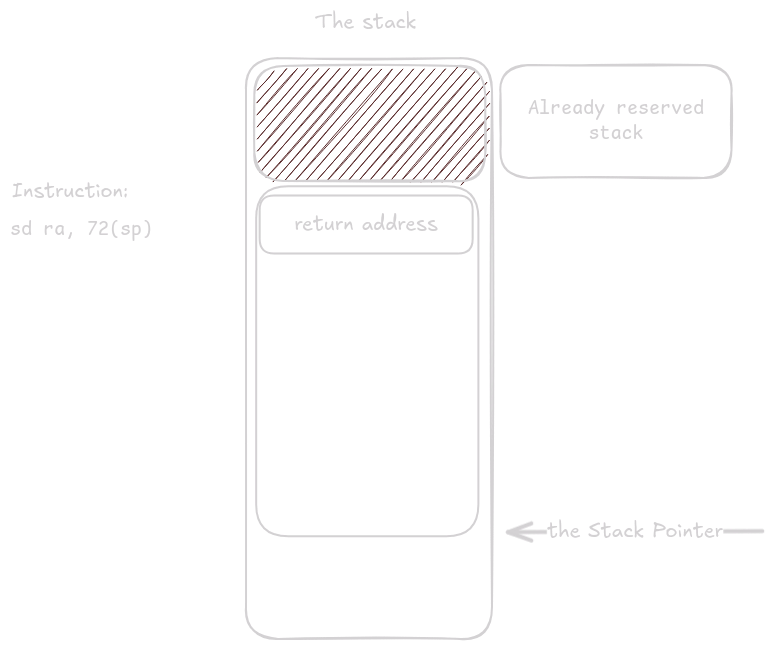
Poté se adresa proměnné buf musí uloží do registru a0.
K sp se přičte 12 a uloží se do a0, tím zůstane přesně 60 bytů místa mezi tím kam ukazuje a0 a a kde ra je na stacku uložno.
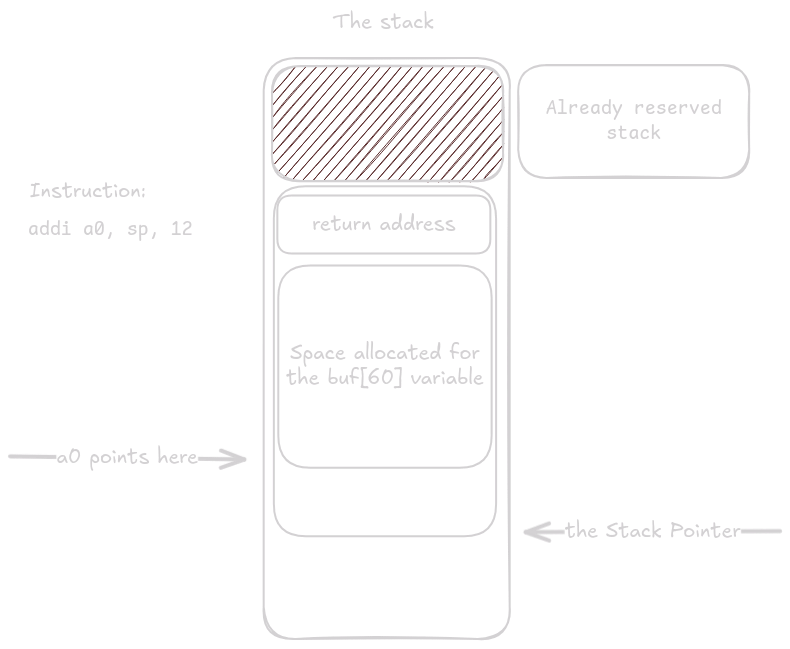
Zbytek argumenů pro fgets se uloží na určená místo a fgets() je zavoláno.
Poté co fgets() vrátí bude buf naplněný charaktery z standard input.
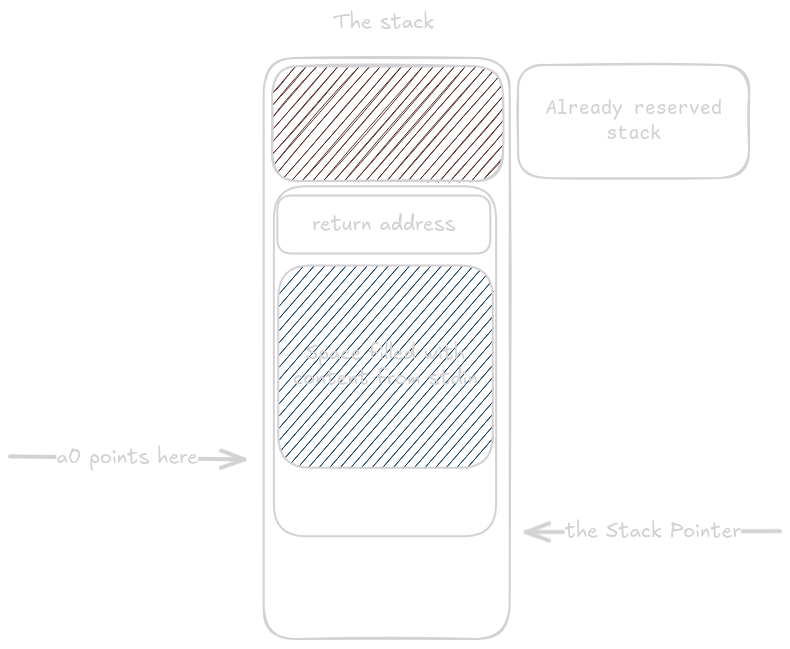
Na konci funkce se buffer prostě zahodí a není na nic využitý (tohle je přece jenom pouze ukázka ne komplexní program).

Nyní zkombinujeme vše, co jsme se do teď na učily pro tento poslední příklad se stackem. (Poznámka: v jazyce C se obvykle místo vracení takovéto hodnoty používají tzc. out parametry. Pokud by funkce brala jako první argument out parametr, vygenerované assembly by vypadalo v podstatě stejně).
struct triple_long {
long a;
long b;
long c;
};
struct triple_long tl(long x) {
struct triple_long t = {0};
t.b = x;
return t;
}
void tl_print() {
struct triple_long b = tl(3);
printf("%li\n", b.a);
}tl:
li a2, 0
sd a2, 0(a0)
sd a1, 8(a0)
sd a2, 16(a0)
ret
tl_print:
addi sp, sp, -32
sd ra, 24(sp)
mv a0, sp
li a1, 3
call tl
ld a1, 0(sp)
.Lpcrel_hi2:
auipc a0, %pcrel_hi(.L.str)
addi a0, a0, %pcrel_lo(.Lpcrel_hi2)
ld ra, 24(sp)
addi sp, sp, 32
tail printf
.L.str:
.asciz "%li\n"Jako vždky místo na stacku je alokováno a ra je uloženo na stack.
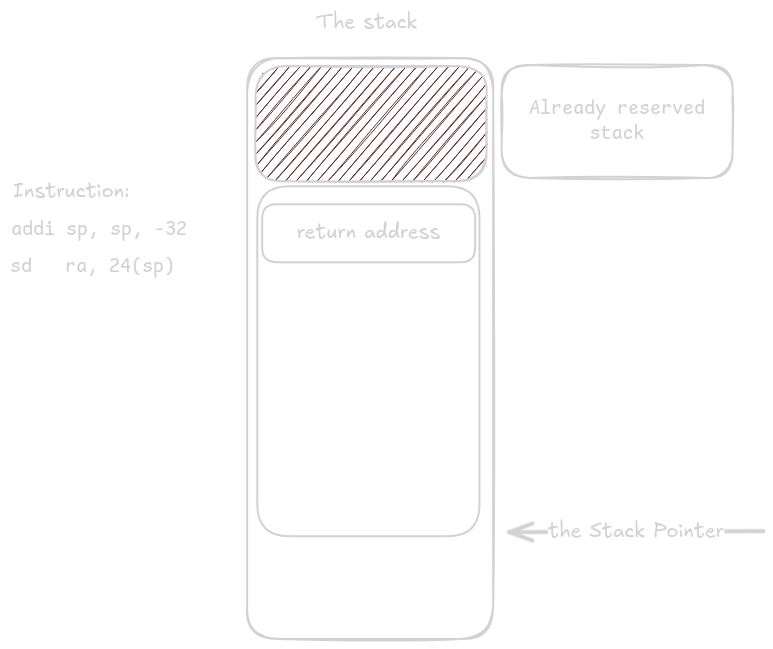
Místo na stacku bylo zarezervováno jak pro registr ra, tak pro proměnnou b.
Protože funkce tl() vrací hodnotu, kterou nelze vrátit v jednom nebo dvou registrech, očekává jako první argument adresu, kam má být návratová hodnota umístěna.
Přesunutím sp do a0, přesně tohoto protože tím zůstane přesně 24 bajtů místa pro struct triple_long na stacku.
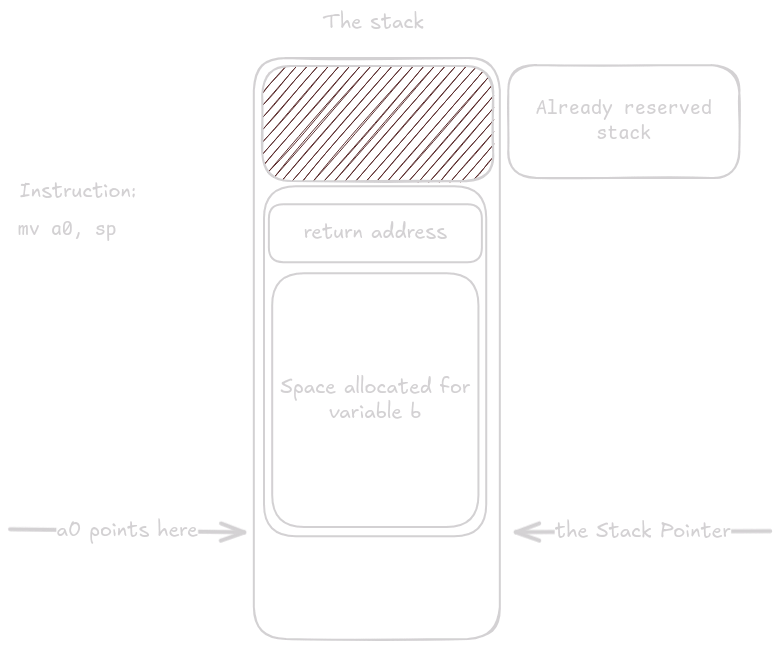
Po umístění argumentů se zavolá funkce tl().
Protože funkce tl() je listová funkce, nepotřebuje prolog ani epilog.
Jediné co teď musí funkce udělat je vyplnit přiřazené místo správnými hodnotami.
Jak vidíte, instrukce se zapisují do offsetu od a0 a ne do sp, protože funkce si není vědoma, že místo, kam se má psát, je na stacku.
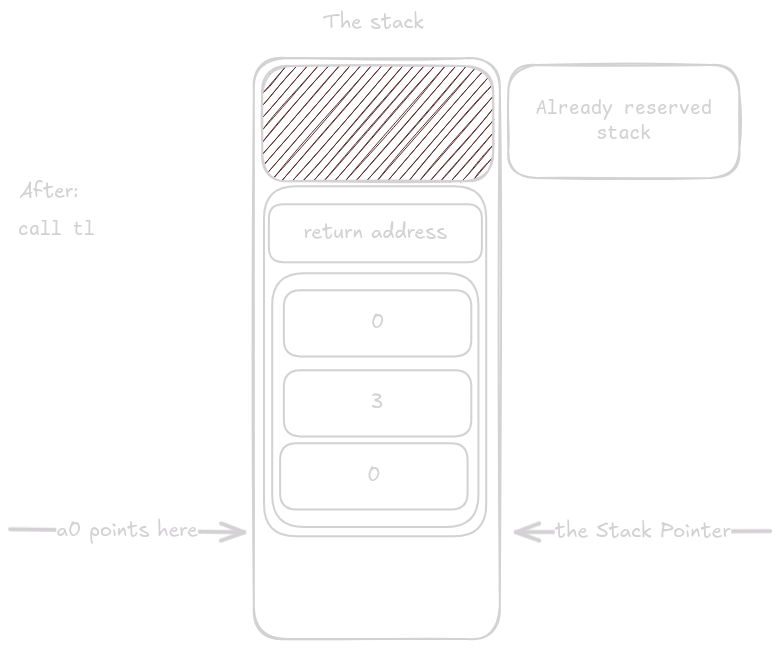
Nyní se stane něco zvláštního. Funkce načte argumenty pro printf() na určené pozice, ale pak spustí epilog funkce.
Jedná se o optimalizaci provedenou kompilátorem, která se nazývá tail call optimization.
Instrukce ld ra, 24(sp) načte do ra návratovou adresu volajícího, který zavolal tl_print().
Funkce tail je speciální typ volání, který nemění hodnotu registru ra, takže když se ve funkci printf() spustí instrukce ret, pc se vrátí do funkce, která volala tl_print().
To šetří místo na zásobníku, toto je výhodné při vnořeném volání a zejména při rekurzivním volání.
Nyní printf() využívá stejný prostor, který předtím využívala funkce tl_print().
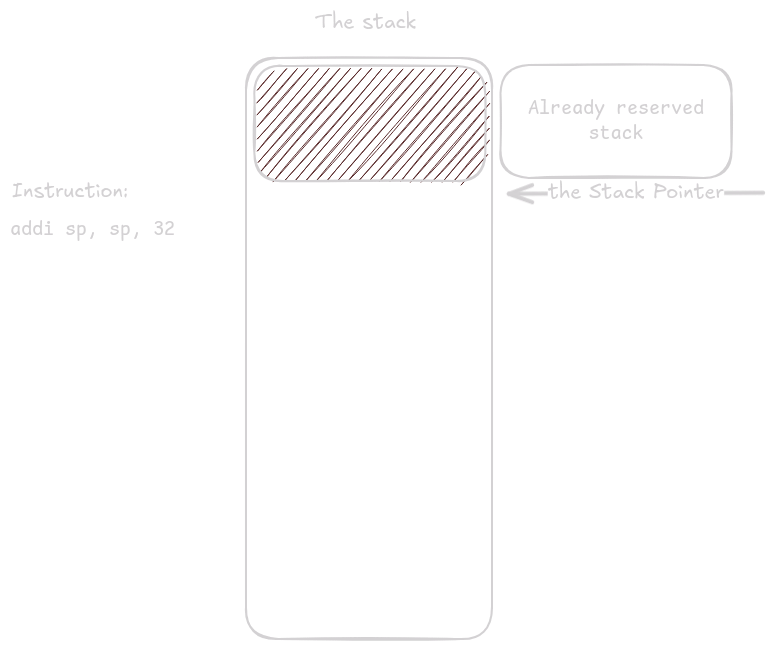
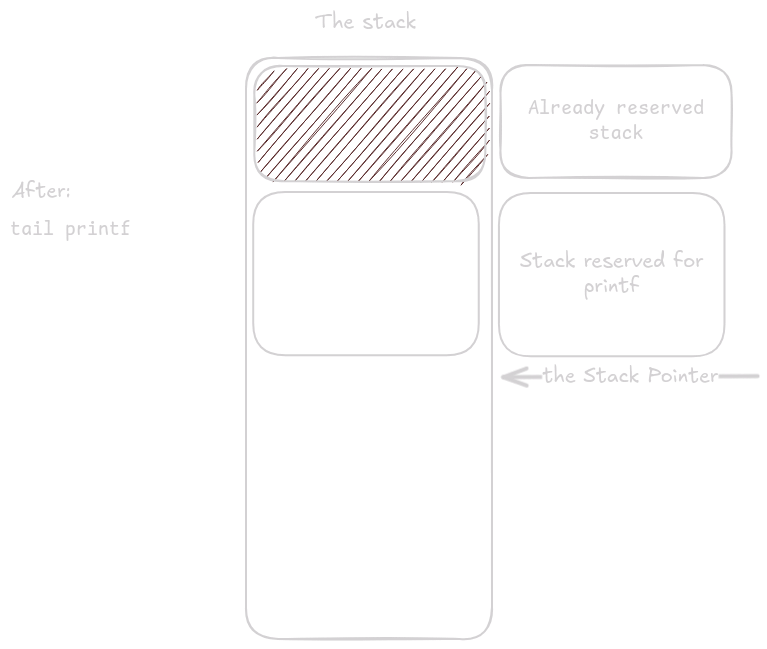
Programování operačních systémů
Takže teď když víte jak funguje assembler je čas dekompilovat všechny binárky na světě a hacknout Pentagon.
Zpomal, ne tak rychle, ty binárky neběží jen tak na procesoru, ale pod operačním systémem, což přidává další vrstvu složitosti.
I když nechcete hackovat Pentagon, je stále velmi užitečné rozumět operačním systémům při debudování nebo při binary exploitation pro CTF.
V této sekci vám vysvětlím některé důležité konepty v Linuxu a na konci vám ukážu, jak napsat jednoduchý klon programu cat pouze pomocí assembleru bez jakékoliv externí pomoci (téměř bez jakékoliv extréní pomoci).
Pokud chcete sledovat příklady, nejjednodušší je si nastavit risc-v virtuálku pomocí tohoto návodu.
Syscally
Doposud jsem mluvil o tom jak můžeme sčítat, odečítat, skákat, volat, načístat a ukládat na stack, ale jak můžeme čistě s tímhle něco vypsat na terminál.
A tím myslím čistě s tímhle žádný volání na printf()
No je to jednoduché, nemůžete, abych byl přesnější, nemůžete sami.
Potřebujete pomoc operačního systému.
Pokud chcete číst, zapisovat nebo si vyžádat více paměti, musíte o to požádat systém.
Dokonce i když chcete skončit a ukončit program, musíte požádat systém.
Zde je jednoduchý program Hello World používající pouze syscally.
.section .data # section which contains already initialized data of our program
hello:
.asciz "Hello, World!\n"
.section .text # section which stores the code of our binary
.globl _start # this is directive which makes the _start symbol accessible outside of the binary
_start:
li a0, 1 # file descriptor
la a1, hello # data
li a2, 14 # length
li a7, 64 # write syscall number
ecall
li a0, 0 # exit code
li a7, 93 # exit syscall number
ecallArgumenty načítáme, jako bychom volali jakoukoli jinou funkci, rozdíl je pouze v posledním argumentu.
Posledním argumentem v a7 je číslo syscall.
Chcete-li zjistit, které syscally jsou k dispozici a jejich čísla, můžete se podívat zde nebo zde.
Čísla jsou závislá na architektuře a systému, takže na x86 budou tato čísla jiná.
Abychom zjistili, jak syscall volat, musíme se podívat do dokumentace jaké argumenty syscall očekává.
Každý syscall má svou vlastní manuálovou stránku, na kterou se můžete podívat tak, že napíšete man 2 <jméno syscall> do terminálu (pokud se chcete o manuálových stránkách dozvědět více, napište man man).
Pokud se podíváme na man 2 write, najdeme type signature syscall ssize_t write(int fd, const void buf[.count], size_t count);.
Argumenty poté musíme podle calling convention naskládat na určená místa.
První argument int fd je file descriptor, ze kterého máme číst.
V tomto příkladu používáme descriptor souboru 1, což je vždy standardní výstup.
Dalším argumentem je pointer na buffer obsahující data pro zápis a třetím argumentem je množství dat, které má být zapsáno.
V tomto případě chceme data z label hello a z odsud chceme přečíst 14 bytů (délka stringu Hello World\n)
Po vložení argumentů včetně čísla syscallu můžeme jen napsat instrukci ecall a nechat systém, aby se postaral o zbytek.
Syscally obvykle nevoláme ručně ani v C ani v assembly.
Obvykle se používá wrapper kolem syscallů, jako je fgets(), který byl použit v příkladu výše, nebo printf(), který poskytuje mnohem více funkcí.
Tyto wrappery také mohou provádět další kontroly, aby bylo syscall optimálnější.
Jen si uvědomte, že syscall jsou C funkce uvnitř kernelu, pokud píšete assembler ručně z nějákého důvodu, musíte při před voláním uložit registry které vám neuloží syscall samotný (stejně jako kdyby jste volali normální funkci).
Stránkování
Dosud jsme se zabývali pouze daty s konstantní velikosti, ale co když chceme uložit něco jako vector, jehož velikost se může kdykoli změnit. Nemůžeme jej umístit na zásobník, kde jsou data úhledně naskládána na sobě. Zde přicházejí ke slovu stránky (v angličtině pages), které si můžete vyžádat od systému a získat tak další paměť "jen tak".
Stránkování (v angličině paging) nám poskytuje dvě velké výhody: Fragmentace není problém a nevidíte do paměti jiných procesů. Když si vyžádáte stránku, dostanete zpět pointer, který je ukazuje na váš virtuální adresový prostor. V linuxu a na většině moderních systémech jednotlivé procesy nesdílejí adresový prostor a namísto toho každý proces má svůj vlastní virtuální prostor do kterého ostatní procesy nevidí a který je namapovaný na fyzickou paměť.
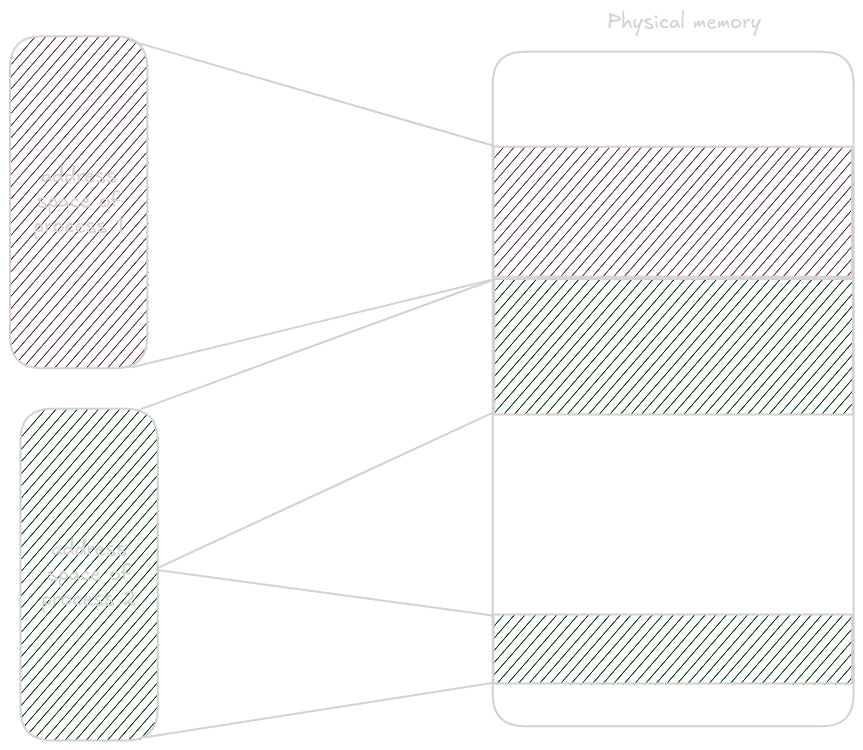
Tímto se výrazně zvýší bezpečí jednotlivých procesů protože ti jen tak nemůže někdo přečíst tvoji pamět. Zároveň paměť procesu může být rozdělena na dvě místa v fyzycké paměti aniž by o tom proces věděl.
Způsob jakým to funguje je že fyzická paměť je rozdělená na stránky a tyto fyzické stránky jsou skrz memory management unit mapovány na virtuální pages.
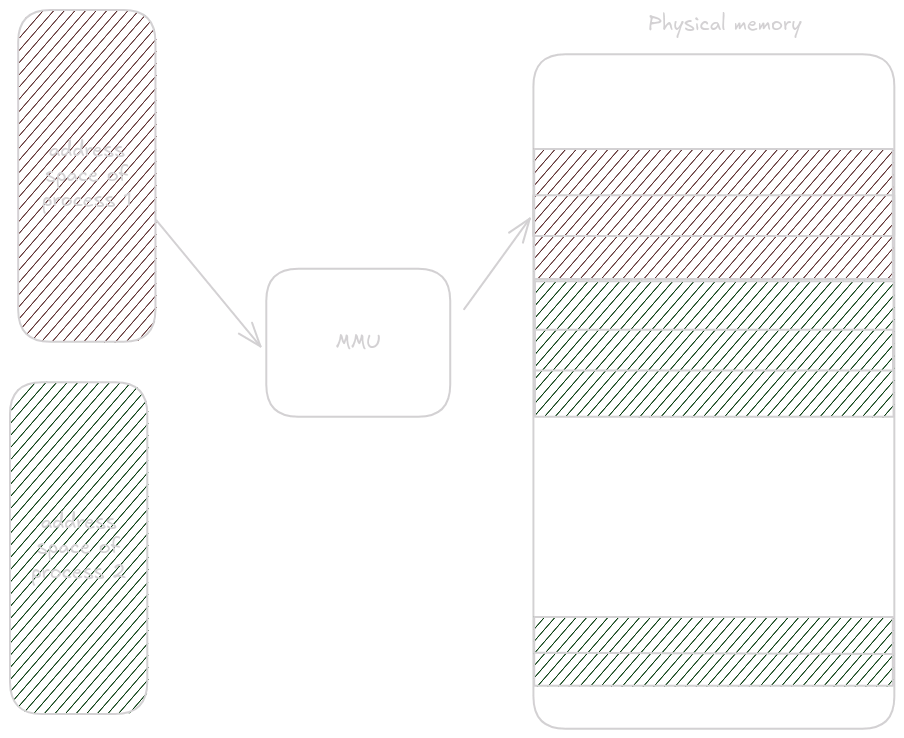
Velikost stránky v Linuxu je obvykle 4096 bajtů, což můžete ověřit zadáním getconf PAGE_SIZE do terminálu.
4096 bajtů lze adresovat pomocí 12 bitů, takže při překladu z virtuální adresy na virtuální na fyzickou se posledních 12 bitů zkopíruje z virtuální do fyzické adresu.
Zbytek je přeložen skrz memory management unit.
Pro vyžádání stránky v assembleru použijeme syscall mmap a poté syscall munmap, kterým řekneme, že stránku již nechceme.
Co tyto argumenty znamenají, najdete v dokumentaci man 2 mmap.
Nejdůležitější je arugument fd -1, který říká, že stránka není založená na souboru, ale že má být z paměti.
.section .text
.global _start
_start:
# Get the page
li a0, 0 # NULL address hint
li a1, 4096 # length of the page
li a2, 3 # PROT_READ | PROT_WRITE
li a3, 34 # MAP_PRIVATE | MAP_ANONYMOUS
li a4, -1 # fd argument for mmap
li a5, 0 # offset argument for mmap
li a7, 222 # syscall number for mmap
ecall
# The address where the page is mapped is in a0
# Save it for later unmapping
mv s0, a0
# Unmapping the page
mv a0, a1 # Move mmap address to a0
li a1, 4096 # length of the page
li a7, 215 # syscall number for munmap
ecall
# Exit
li a7, 93 # syscall number for exit
li a0, 0 # exit code 0
ecallPro build spusťte tento příkaz: as mmap.asm -o mmap.o; ld mmap.o -o mmap
Psaní cat v assembly
Pro build následujících příkladů použijte následující příkazy as cat.asm -o cat.o; gcc cat.o -o cat.
gcc přidá kód, který volá funkci main (tu budeme muset napsat) s tímto type signature int main(int argc, char *argv[]).
To nám umožní mnohem snazší přístup k argumentům, které byly předány binárce (mohli bychom je získat ručně, ale to je zbytečně těžší).
Napíšeme si zjednodušenou verzi cat, která vypíše obsah souboru, který byl zadán jako první argument.
Takže tento ./cat cat.asm by vypsal obsah obsahu souboru cat.asm.
Otevřeme soubor uvedený jako argument, vyžádáme si stránku od systému, pak projdeme soubor ve smyčce, načteme soubor do dané stránky a obsah stránky vypíšeme na standardní výstup.
Nejprve musíme definovat out .section .text, kde se má kód začít provádět.
Také naše hlavní funkce by měla být označena jako globální, aby ji gcc mohl při linkování najít.
.section .text
.globl main
main:Poté začne prolog naší funkce, vzhledem k tomu že budeme volat syscally musíme uložit ra registr.
addi sp, sp, -16
sd ra, 8(sp)Pokud budeme potřebovat jiné registry které máme povinost uschovat musíme udělat více místa na stacku a přidat jejich uložení do prologu.
Nyní chceme zkontrolovat, zda bylo zadáno správné množství argumentů.
Hodnota int argc je prvním argumentem funkce main, takže bude v registru a0.
Počet argumentů by měl být dva, protože pokud je binární soubor volán takto ./cat cat.asm, argumenty v int argv budou vypadat takto ["./cat", "cat.asm"]
# Check if the number of arguments is correct
li t0, 2 # Number of arguments
bne a0, t0, .error_exitOk teď napíšeme .error_exit který nastaví návratovou hodnotu na error a ukončí program.
.error_exit:
# Exit with error code (-1)
li a0, -1 # exit code
j .epilogueA samozřejmě .epilogue
.epilogue:
ld ra, 8(sp)
addi sp, sp, 16
retNezapomeňte že kdykoliv změníte prolog musíte změnit i epilog.
To co máme v tuto chvíli by mělo vypadat nějak takhle:
.section .text
.globl main
main:
addi sp, sp, -16
sd ra, 8(sp)
# Check if the number of arguments is correct
li t0, 2 # Number of arguments
bne a0, t0, .error_exit
# This is where the rest of the function will go
.error_exit:
# Exit with error code (-1)
li a0, -1 # exit code
j .epilogue
.epilogue:
ld ra, 8(sp)
addi sp, sp, 16
retPokud tohle sestavíte a spustíte zjistíte že binárka skončí s jiným exit number podle toho kolik jste jí dali argumentů.
Pro zjištění exit number můžete použít echo $?.
Teď když jsme zkontrolovali že je správný počet argumetnů můžeme otevřít soubor
# Open the file specified in argv[1]
li a0, -100 # a0 = AT_FDCWD
ld a1, 8(a1) # a1 = argv[1]
li a2, 0 # a2 = O_RDONLY
li a7, 56 # syscall number for sys_openat
ecall
# Store file descriptor
mv s0, a0
# Check for open failure
bltz a0, .error_exit-100 jako první argument je speciálně definované číslo v dokumentaci syscallu, které říká, že syscall má cestu k souboru považovat za relativní.
Vrácený deskriptor souboru pak uložíme do s0 (registr musíme přidat do prologu a epilogu).
Nakonec musíme zkontrolovat, zda je deskriptor souboru platný.
Pokud syscall selhal, dokumentace říká, že návratová hodnota je záporná, což je důvod pro bltz a0, .error_exit.
(if a0 is lesser then zero)
Nyní si vyžádáme stránku ze systému.
Na začátek souboru přidáme .section .data, abychom mohli kdykoli změnit velikost stránky.
Také díky tomu existuje pouze jeden zdroj pravdy tom jaká je velikost stránky.
.section .data
buffer_size: .quad 4096 # Define the buffer size for readingPro získání stránky zavoláme syscall mmap.
# Allocate memory using mmap
li a0, 0 # NULL address hint
ld a1, buffer_size # Get buffer_size
li a2, 3 # PROT_READ | PROT_WRITE
li a3, 34 # MAP_PRIVATE | MAP_ANONYMOUS
li a4, -1 # fd argument for mmap
li a5, 0 # offset argument for mmap
li a7, 222 # syscall number for mmap
ecall
# Store mmap address
mv s1, a0
# Check for mmap failure
bgez a0, .read_loop
# Exit with error code if mmap failed
j .error_exitPokud je návratová hodnota kladná, začneme soubor číst, jinak skončíme s chybou.
Do registru s1 ukládáme adresu stránky, registr opět musíme přidat do prologu a epilogu.
Nyní začneme psát .read_loop.
.read_loop:
# Read from file
mv a1, s1 # Move mmap address to a1
ld a2, buffer_size # Get buffer_size
mv a0, s0 # Move file descriptor to a0
li a7, 63 # syscall number for read
ecall
# Check if read returned 0 (EOF)
beq a0, zero, .epilogue
# Check for read errors
blt a0, zero, .error_exitNejprve načteme buffer_size bytů ze souboru (file descriptor v s0) do stránky (pointer v s1).
Syscall read zachovává stav toho, jak daleko jsme četli, takže když jej zavoláme znovu, začne číst tam, kde naposledy skončil.
Díy tomů můžeme číst v smyčce a přečíst tak celý soubor.
Návratová hodnota je určena jako množství přečtených bajtů v případě že syscall uspěje, pokud je hodnota nulová, znamená to, že jsme na konci souboru, a záporná hodnota znamená chybu.
Hned pro čtení chceme zapsat do standard output obsah stránky.
.read_loop:
# Read from file
mv a1, s1 # Move mmap address to a1
ld a2, buffer_size # Get buffer_size
mv a0, s0 # Move file descriptor to a0
li a7, 63 # syscall number for read
ecall
# Check if read returned 0 (EOF)
beq a0, zero, .epilogue
# Check for read errors
blt a0, zero, .error_exit
# Write to stdout
mv a2, a0 # Number of bytes to write
mv a1, s1 # Read from the page
li a0, 1 # File descriptor 1 (stdout)
li a7, 64 # syscall number for write
ecall
# Continue reading
j .read_loopMnožství přečtených bytů je před syscall write v registru a0 (sem ho vrátil syscall read).
Syscall write očekává množství bytů k zápisu v registru a2.
V a0 je uložen deskriptor souboru, do kterého chceme zapisovat, v tomto případě chceme zapisovat do standardního výstupu, což je vždy deskriptor souboru 1.
A chceme číst data ze stránky uložené v s1.
Poslední změnu provedeme ve větvi která nastane v případě že jsme na konci souboru. Je dobrým zvykem soubor zavřít a stránku odmapovat v chvíli kdy s nima přestaneme pracovat. Branch tedy nepůjde na rovnou na epilog ale ještě před tím po sobě program uklidí:
# Check if read returned 0 (EOF)
beq a0, zero, .close_fd.close_fd:
# Close the file descriptor
mv a0, s0 # Move file descriptor to a0
li a7, 57 # syscall number for close
ecall
# Unmap memory
mv a0, a1 # Move mmap address to a0
ld a1, buffer_size # Get buffer_size
li a7, 215 # syscall number for munmap
ecall
li a0, 0 # exit code
j .epilogueNyní jsme po sobě uklidily a vše je hotovo.
Finální kód by měl vypadat takto:
.section .data
buffer_size: .quad 4096 # Define the buffer size for reading
.section .text
.globl main
main:
addi sp, sp, -32
sd ra, 24(sp)
sd s0, 16(sp)
sd s1, 8(sp)
# Check if the number of arguments is correct
li t0, 2 # Number of arguments
bne a0, t0, .error_exit
# Open the file specified in argv[1]
li a0, -100 # a0 = AT_FDCWD
ld a1, 8(a1) # a1 = argv[1]
li a2, 0 # a2 = O_RDONLY
li a7, 56 # syscall number for sys_openat
ecall
# Store file descriptor
mv s0, a0
# Check for open failure
bltz a0, .error_exit
# Allocate memory using mmap
li a0, 0 # NULL address hint
ld a1, buffer_size # Get buffer_size
li a2, 3 # PROT_READ | PROT_WRITE
li a3, 34 # MAP_PRIVATE | MAP_ANONYMOUS
li a4, -1 # fd argument for mmap
li a5, 0 # offset argument for mmap
li a7, 222 # syscall number for mmap
ecall
# Store mmap address
mv s1, a0
# Check for mmap failure
bgez a0, .read_loop
# Exit with error code if mmap failed
j .error_exit
.read_loop:
# Read from file
mv a1, s1 # Move mmap address to a1
ld a2, buffer_size # Get buffer_size
mv a0, s0 # Move file descriptor to a0
li a7, 63 # syscall number for read
ecall
# Check if read returned 0 (EOF)
beq a0, zero, .close_fd
# Check for read errors
blt a0, zero, .error_exit
# Write to stdout
mv a2, a0 # Number of bytes to write
mv a1, s1 # Read from the page
li a0, 1 # File descriptor 1 (stdout)
li a7, 64 # syscall number for write
ecall
# Continue reading
j .read_loop
.close_fd:
# Close the file descriptor
mv a0, s0 # Move file descriptor to a0
li a7, 57 # syscall number for close
ecall
# Unmap memory
mv a0, a1 # Move mmap address to a0
ld a1, buffer_size # Get buffer_size
li a7, 215 # syscall number for munmap
ecall
li a0, 0 # exit code
j .epilogue
.error_exit:
# Exit with error code (-1)
li a0, -1 # exit code
j .epilogue
.epilogue:
ld ra, 24(sp)
ld s0, 16(sp)
ld s1, 8(sp)
addi sp, sp, 48
ret